
저는 최근들어 V8 기여 범위를 JS 를 구현하는 영역에서 더 낮은 레이어의 컴파일러 파이프라인으로 확장했습니다.
이 파이프라인은 바이트코드를 받아 기계어 코드를 생성하거나, 다음 컴파일러를 위한 새로운 그래프를 생성하는 역할을 합니다. 이 파이프 라인은 각각 Maglev와 Turbolev라고 불립니다.
이 글에서는 제가 어떻게 기여 영역을 확장했고, Turbolev 프로젝트에 어떤 기여를 했는지 설명할 것 입니다.
Backgrounds
V8과 JIT
V8은 크롬, NodeJS, Deno 등 많은 곳에서 사용되는 자바스크립트 엔진입니다. V8은 multi-tiering JIT 컴파일러를 가지고 있습니다. Just-in-time, 즉 JIT 컴파일은 프로그램 실행 전이 아닌 실행 중에 코드를 실시간으로 컴파일하는 방식입니다. [FYI: Wikipedia]
예를 들어, 아래 코드는 바이트코드로 컴파일 되어 바이트 코드가 가상 머신에서 실행됩니다. 다시 말해 실제 기계어가 아니라는 뜻 입니다.
Code:
function add(a, b) {
return a + b;
}
add(1, 2);
Bytecode:
devsdk@dave ~/workspace/chromium/v8/v8 % ./out/arm64.release/d8 ~/workspace/chromium/playground/add.js --print-bytecode
[generated bytecode for function: (0x2f3e0005d7cd <SharedFunctionInfo>)]
Bytecode length: 28
Parameter count 1
Register count 4
Frame size 32
0xaef00100084 @ 0 : 13 00 LdaConstant [0]
0xaef00100086 @ 2 : cf Star1
0xaef00100087 @ 3 : 1b fe f7 Mov <closure>, r2
0xaef0010008a @ 6 : 6d 6f 01 f8 02 CallRuntime [DeclareGlobals], r1-r2
0xaef0010008f @ 11 : 23 01 00 LdaGlobal [1], [0]
0xaef00100092 @ 14 : cf Star1
0xaef00100093 @ 15 : 0d 01 LdaSmi [1]
0xaef00100095 @ 17 : ce Star2
0xaef00100096 @ 18 : 0d 02 LdaSmi [2]
0xaef00100098 @ 20 : cd Star3
0xaef00100099 @ 21 : 6b f8 f7 f6 02 CallUndefinedReceiver2 r1, r2, r3, [2]
0xaef0010009e @ 26 : d0 Star0
0xaef0010009f @ 27 : b5 Return
Constant pool (size = 2)
0xaef0010004d: [TrustedFixedArray]
- map: 0x2f3e00000605 <Map(TRUSTED_FIXED_ARRAY_TYPE)>
- length: 2
0: 0x2f3e0005d81d <FixedArray[2]>
1: 0x2f3e00003e8d <String[3]: #add>
Handler Table (size = 0)
Source Position Table (size = 0)
[generated bytecode for function: add (0x2f3e0005d82d <SharedFunctionInfo add>)]
Bytecode length: 6
Parameter count 3
Register count 0
Frame size 0
0xaef001000c8 @ 0 : 0b 04 Ldar a1
0xaef001000ca @ 2 : 3f 03 00 Add a0, [0]
0xaef001000cd @ 5 : b5 Return
Constant pool (size = 0)
Handler Table (size = 0)
Source Position Table (size = 0)
위 바이트코드는 V8 가상 머신에서 기계어 코드처럼 동작합니다. 하지만 실제 기계어는 아닙니다.
함수가 충분히 “뜨거워”지면(자주 호출되면), JIT 컴파일러는 더 빠른 실행을 위해 이를 네이티브 기계어 코드로 최적화합니다.
function add(a, b) {
return a + b;
}
%PrepareFunctionForOptimization(add);
add(1,2);
%OptimizeFunctionOnNextCall(add);
add(1,2);
add 함수는 다음과 같이 컴파일됩니다:
devsdk@dave ~/workspace/chromium/v8/v8 % ./out/arm64.release/d8 ~/workspace/chromium/playground/add.js --allow-natives-syntax --turbofan --print-opt-code
--- Raw source ---
(a, b) {
return a + b;
}
--- Optimized code ---
optimization_id = 0
source_position = 12
kind = TURBOFAN_JS
name = add
compiler = turbofan
address = 0x2be2001001d5
Instructions (size = 288)
0x140000020 0 a9bf7bfd stp fp, lr, [sp, #-16]!
0x140000024 4 910003fd mov fp, sp
0x140000028 8 a9be03ff stp xzr, x0, [sp, #-32]!
0x14000002c c a9016fe1 stp x1, cp, [sp, #16]
0x140000030 10 f8520342 ldur x2, [x26, #-224]
.-') .-. .-') _ (`-. _ (`-. ('-. _ .-') _
( OO ). \ ( OO ) ( (OO ) ( (OO ) _( OO)( ( OO) )
(_)---\_),--. ,--. ,-.-') _.` \ _.` \(,------.\ .'_
/ _ | | .' / | |OO)(__...--''(__...--'' | .---',`'--..._)
\ :` `. | /, | | \ | / | | | / | | | | | | \ '
'..`''.)| ' _) | |(_/ | |_.' | | |_.' |(| '--. | | ' |
.-._) \| . \ ,| |_.' | .___.' | .___.' | .--' | | / :
\ /| |\ \(_| | | | | | | `---.| '--' /
`-----' `--' '--' `--' `--' `--' `------'`-------'
/* 100줄이 넘는 기계어 코드가 있어 생략되었습니다 */
0x14000013c 11c 97fffffb bl #-0x14 (addr 0x140000128)
Inlined functions (count = 0)
Deoptimization Input Data (deopt points = 4)
index bytecode-offset pc
0 2 NA
1 2 NA
2 2 NA
3 -1 9c
Safepoints (stack slots = 6, entries = 2, byte size = 24)
0x1400000bc 9c slots (sp->fp): 100000 deopt 3 trampoline: 11c
0x1400000e4 c4 slots (sp->fp): 000000
RelocInfo (size = 13)
0x1400000b4 full embedded object (0x0263000446c5 <NativeContext[301]>)
0x1400000b8 near builtin entry
0x1400000e0 near builtin entry
0x140000110 constant pool (size 16)
--- End code ---
위에 있는 코드는 V8의 현재 최상위 티어 JIT 컴파일러인 Turbofan과 Turboshaft를 사용한 예시입니다.
Maglev와 Turbofan
앞서 언급했듯이 V8은 multi-tier JIT 컴파일러를 가지고 있습니다. Maglev는 중간 티어 JIT 컴파일러입니다. Turbofan과 Turboshaft는 높은 수준의 최적화된 코드를 생성하지만 컴파일하는 데 시간이 더 오래 걸립니다.
| Compiler | Compile Speed | Optimization Level | Structure |
|---|---|---|---|
| Maglev | 빠름 | 낮은 최적화 | 단순 |
| Turbofan | 느림 | 높은 최적화 | 복잡 |
V8의 tiering manager는 결정 로직에 따라 주어진 함수에 대해 티어를 적용합니다.
Turbolev
이름은 maglev + turboshaft에서 유래했습니다. 이 프로젝트는 Maglev의 IR(중간 표현)을 사용하여 기존의 Turbofan 컴파일러 프론트엔드를 대체하는 것을 목표로 하고 있습니다.
이전의 최상위 티어 JIT 컴파일러는 프론트엔드로 Turbofan을, 백엔드로 Turboshaft를 사용했습니다. Turbofan은 기존의 일반적인 CFG(Control Flow Graph) 기반 접근 방식이 아닌 Sea of Nodes를 최적화에 사용했습니다. 이는 이론적으로는 강력하지만, 복잡성과 유지보수성 측면에서 몇 가지 실용적인 단점이 있었습니다.
더 자세한 배경과 프로젝트의 시작에 대해 읽어보려면: Darius의 Land ahoy: leaving the Sea of Nodes · V8 를 읽어보세요. :)
저는 어떻게 이 프로젝트에 참여하게 되었을까요?
저는 몇 년 동안 V8 프로젝트의 JS 기능 영역에 기여해왔습니다. 하지만 메모리 관리와 JIT 컴파일러는 여전히 ‘블랙박스’처럼 느껴졌습니다. 외부 기여자로서, 새로운 ECMAScript 기능을 구현할 기회를 찾기가 점점 더 어려워지기도 했고 더 많은 영역에 기여하고 싶어서 블랙박스 내부를 들여다보기 위해 기여 영역을 확장하기로 결정했습니다.
과거 Float16Array CL JIT 부분을 리뷰해 줬던 적이 있는 Darius가 기억 났고, 최근에 v8.dev에 turbolev에 대한 글을 게시한 것을 봤습니다. 저는 제가 도울 일이 있는지 알아보기 위해 이메일을 보냈습니다.
Hi Darius,
I’ve noticed that it’s getting a bit tough to find contribution opportunities related to ECMAScript features as an external contributor. So I was wondering—are there any areas in the compiler side (like Turboshaft or Maglev), or GC/memory stuff, where I could possibly help out?
I’d love to learn more and hopefully get involved in a broader range of work in V8.
–
Regards,
Seokho
Darius 는 친절하게 Turbolev 프로젝트를 제안해줬습니다. 친절한 가이드에 따라 Turbolev 프로젝트에 참여하기로 마음을 먹었고 가장 온보딩하기 수월한 구현을 찾아보려 했습니다.
그렇게 첫번째 기여 목표를 찾아 나섰고, 찾은것은 Math.atan2 였는습니다. 이 함수는 비슷한 IEEE754 Binary 연산을 처리하는 Math.pow 기존 구현 경로가 있었기 때문입니다.
저는 CL 초안을 만들어 Darius, Marja, Victor, Leszek에게 질문이 담긴 이메일을 보냈고, 답변을 통해 친절한 설명 및 성능 측정 도구인 Pinpoint 관련 도움등을 받을 수 있었습니다.
기여 내용
Math.atan2 최적화를 시작으로 약 4개의 CL에 기여했습니다.

제가 최적화한 내용은 다음과 같습니다:
Math.atan2Math.sqrt- `Array.prototype.at
… 및 리팩토링.
그중 하나를 소개합니다 - Implement Math.sqrt turbolev Math.sqrt 함수를 mid, top tier JIT 컴파일러가 지원할 수 있도록 개선했습니다.
Pinpoint에 따르면 성능이 61% 향상되었습니다.
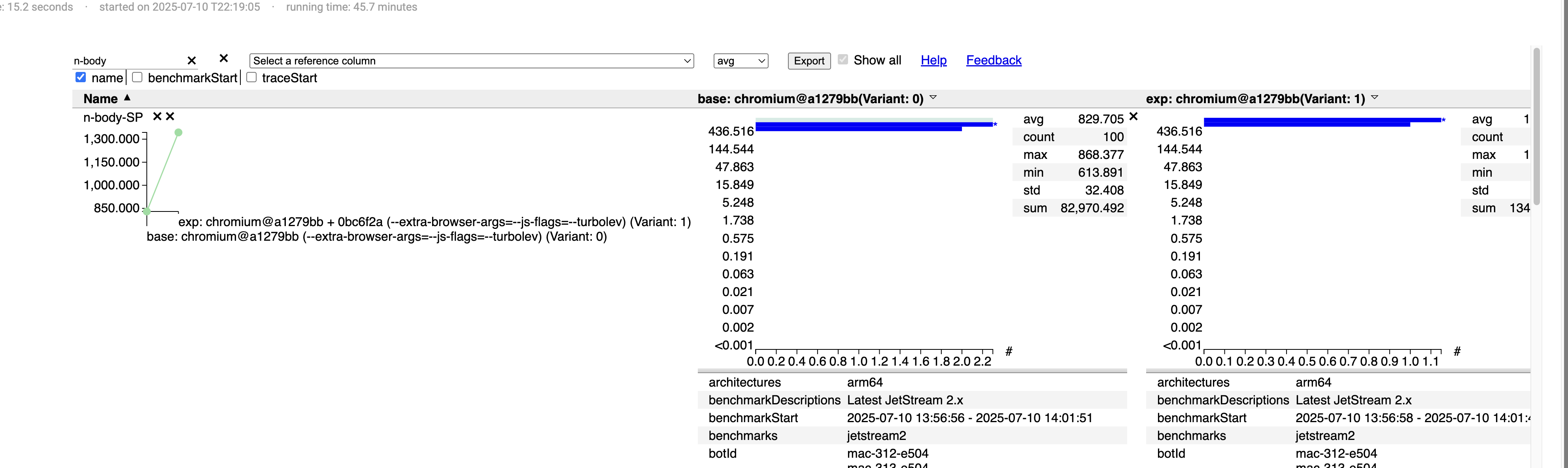
Victor는 코드리뷰 과정에서 Amazing이라는 표현을 쓸 정도였습니다 ㅎㅎ.

이 최적화 과정을 풀어서 설명해보자면:
Floa64Sqrt maglev IR 노드를 추가했습니다.
class Float64Sqrt : public FixedInputValueNodeT<1, Float64Sqrt> {
using Base = FixedInputValueNodeT<1, Float64Sqrt>;
public:
explicit Float64Sqrt(uint64_t bitfield) : Base(bitfield) {}
static constexpr OpProperties kProperties = OpProperties::HoleyFloat64();
static constexpr
typename Base::InputTypes kInputTypes{ValueRepresentation::kHoleyFloat64};
Input& input() { return Node::input(0); }
void SetValueLocationConstraints();
void GenerateCode(MaglevAssembler*, const ProcessingState&);
void PrintParams(std::ostream&) const;
};
그리고 maglev 그래프 빌더에 MathSqrt를 등록했습니다.
...
V(MathRound) \
V(MathSqrt) \
V(MathClz32) \
V(SetPrototypeHas) \
...
이 매크로는 리듀서 함수를 선언합니다. C++ 컴파일러가 해당 함수의 구현부가 없는 것을 알려줍니다.
MaybeReduceResult MaglevGraphBuilder::TryReduceMathSqrt(
compiler::JSFunctionRef target, CallArguments& args) {
if (args.count() < 1) {
return GetRootConstant(RootIndex::kNanValue);
}
if (!CanSpeculateCall()) {
ValueRepresentation rep = args[0]->properties().value_representation();
if (rep == ValueRepresentation::kTagged) return {};
}
ValueNode* value =
GetFloat64ForToNumber(args[0], NodeType::kNumber,
TaggedToFloat64ConversionType::kNumberOrUndefined);
return AddNewNode<Float64Sqrt>({value});
}
이 리듀서는 Math.sqrt 같은 고수준 연산을 더 최적화된 저수준 IR 노드인 Float64Sqrt로 변환하는 역할을 합니다. 이 노드는 최상위 티어 JIT인 “turbolev”와 중간 티어 JIT인 “maglev”에서 사용될 것입니다.
Mid Tier Maglev - arm64:
void Float64Sqrt::SetValueLocationConstraints() {
UseRegister(input());
DefineSameAsFirst(this);
}
void Float64Sqrt::GenerateCode(MaglevAssembler* masm,
const ProcessingState& state) {
DoubleRegister value = ToDoubleRegister(input());
DoubleRegister result_register = ToDoubleRegister(result());
__ fsqrt(result_register, value);
}
JIT 컴파일할 때, Float64Sqrt 노드는 arm64 아키텍처용 기계어 코드인 fsqrt로 컴파일 합니다. 비슷하게 x64에서는 SSE 명령어인 sqrtsd를 컴파일 할 것 입니다.
For Top-Tier Turbolev 컴파일용:
Float64Sqrt 노드는 turbolev-graph-builder에 의해 소비됩니다.
maglev::ProcessResult Process(maglev::Float64Sqrt* node,
const maglev::ProcessingState& state) {
SetMap(node, __ Float64Sqrt(Map(node->input())));
return maglev::ProcessResult::kContinue;
}
이 코드는 Maglev의 Float64Sqrt 노드를 입력으로 사용하여 Float64Sqrt Turboshaft 그래프 노드를 생성합니다. 여기부터 Turboshaft의 강력한 CFG 기반 백엔드가 Loop Unrolling, Store Elimination, Register Allocation과 같은 추가적인 최적화를 수행하여 더 높은 최적화를 진행합니다.
따라서, Math.sqrt가 hot and stable 상태가 되면, tiering manager는 Turbolev 컴파일을 트리거 합니다. (이 노드는 동일한 기계어 코드를 생성할 것 입니다. 하지만 Turboshaft가 이제 주변의 모든 코드에 강력한 최적화를 적용해 높은 최적화를 이룰 것 입니다.)
Concluding
위에서 언급한 과정을 통해 저는 V8의 Maglev 및 Turbolev 영역에 훨씬 더 익숙해지고, 블랙 박스를 많이 들여다 봤습니다. 하지만 아직 구현되지 않은 함수도 많고, 기여할 수 있는 기회가 많이 보입니다. 앞으로도 계속 기여하여 더 많은 시야를 얻을 수 있을 것 이라고 기대하고 있습니다. 어느날 이 코드베이스가 완전히 익숙해지면 WASM이나 메모리 등 다른 영역으로 또 한번 나아갈 생각입니다.
코드 리뷰를 해주고 좋은 가이드를 해준 동료 Darius, Marja, Victor, Leszek에게 감사 인사 드립니다. :).