
Recently, I expanded my contribution from JS surface layer to lower layer compiler pipeline, which takes a bytecode and produce machine instructions or produce a new graph for the further compiler.
These are called maglev and turbolev.
This post will describe how I expanded my contribution area and merged my first four CLs for the Turbolev project.
Backgrounds
V8 and JIT
V8 is the Javascript Engine that powers Chrome, NodeJS, Deno, … and more. It has multi tiering JIT compiler. A just-in-time (JIT) compilation is compilation (of computer code) during execution of a program (at run time) rather than before execution. [FYI: Wikipedia]
For example, below code will create bytecode and executed in the Virtual Machine. I.e., Not a actual machine instruction.
Code:
function add(a, b) {
return a + b;
}
add(1, 2);
Bytecode:
devsdk@dave ~/workspace/chromium/v8/v8 % ./out/arm64.release/d8 ~/workspace/chromium/playground/add.js --print-bytecode
[generated bytecode for function: (0x2f3e0005d7cd <SharedFunctionInfo>)]
Bytecode length: 28
Parameter count 1
Register count 4
Frame size 32
0xaef00100084 @ 0 : 13 00 LdaConstant [0]
0xaef00100086 @ 2 : cf Star1
0xaef00100087 @ 3 : 1b fe f7 Mov <closure>, r2
0xaef0010008a @ 6 : 6d 6f 01 f8 02 CallRuntime [DeclareGlobals], r1-r2
0xaef0010008f @ 11 : 23 01 00 LdaGlobal [1], [0]
0xaef00100092 @ 14 : cf Star1
0xaef00100093 @ 15 : 0d 01 LdaSmi [1]
0xaef00100095 @ 17 : ce Star2
0xaef00100096 @ 18 : 0d 02 LdaSmi [2]
0xaef00100098 @ 20 : cd Star3
0xaef00100099 @ 21 : 6b f8 f7 f6 02 CallUndefinedReceiver2 r1, r2, r3, [2]
0xaef0010009e @ 26 : d0 Star0
0xaef0010009f @ 27 : b5 Return
Constant pool (size = 2)
0xaef0010004d: [TrustedFixedArray]
- map: 0x2f3e00000605 <Map(TRUSTED_FIXED_ARRAY_TYPE)>
- length: 2
0: 0x2f3e0005d81d <FixedArray[2]>
1: 0x2f3e00003e8d <String[3]: #add>
Handler Table (size = 0)
Source Position Table (size = 0)
[generated bytecode for function: add (0x2f3e0005d82d <SharedFunctionInfo add>)]
Bytecode length: 6
Parameter count 3
Register count 0
Frame size 0
0xaef001000c8 @ 0 : 0b 04 Ldar a1
0xaef001000ca @ 2 : 3f 03 00 Add a0, [0]
0xaef001000cd @ 5 : b5 Return
Constant pool (size = 0)
Handler Table (size = 0)
Source Position Table (size = 0)
This bytecode acts as machine instructions for V8’s Virtual Machine.
When the function becomes “hot” enough (is called frequently), the JIT compiler optimize it into native machine instructions for faster execution.
function add(a, b) {
return a + b;
}
%PrepareFunctionForOptimization(add);
add(1,2);
%OptimizeFunctionOnNextCall(add);
add(1,2);
Function add compiled as:
devsdk@dave ~/workspace/chromium/v8/v8 % ./out/arm64.release/d8 ~/workspace/chromium/playground/add.js --allow-natives-syntax --turbofan --print-opt-code
--- Raw source ---
(a, b) {
return a + b;
}
--- Optimized code ---
optimization_id = 0
source_position = 12
kind = TURBOFAN_JS
name = add
compiler = turbofan
address = 0x2be2001001d5
Instructions (size = 288)
0x140000020 0 a9bf7bfd stp fp, lr, [sp, #-16]!
0x140000024 4 910003fd mov fp, sp
0x140000028 8 a9be03ff stp xzr, x0, [sp, #-32]!
0x14000002c c a9016fe1 stp x1, cp, [sp, #16]
0x140000030 10 f8520342 ldur x2, [x26, #-224]
.-') .-. .-') _ (`-. _ (`-. ('-. _ .-') _
( OO ). \ ( OO ) ( (OO ) ( (OO ) _( OO)( ( OO) )
(_)---\_),--. ,--. ,-.-') _.` \ _.` \(,------.\ .'_
/ _ | | .' / | |OO)(__...--''(__...--'' | .---',`'--..._)
\ :` `. | /, | | \ | / | | | / | | | | | | \ '
'..`''.)| ' _) | |(_/ | |_.' | | |_.' |(| '--. | | ' |
.-._) \| . \ ,| |_.' | .___.' | .___.' | .--' | | / :
\ /| |\ \(_| | | | | | | `---.| '--' /
`-----' `--' '--' `--' `--' `--' `------'`-------'
/* THERE ARE more than 100 liens of machine code; SKIPPED */
0x14000013c 11c 97fffffb bl #-0x14 (addr 0x140000128)
Inlined functions (count = 0)
Deoptimization Input Data (deopt points = 4)
index bytecode-offset pc
0 2 NA
1 2 NA
2 2 NA
3 -1 9c
Safepoints (stack slots = 6, entries = 2, byte size = 24)
0x1400000bc 9c slots (sp->fp): 100000 deopt 3 trampoline: 11c
0x1400000e4 c4 slots (sp->fp): 000000
RelocInfo (size = 13)
0x1400000b4 full embedded object (0x0263000446c5 <NativeContext[301]>)
0x1400000b8 near builtin entry
0x1400000e0 near builtin entry
0x140000110 constant pool (size 16)
--- End code ---
The demonstration above used V8’s current top-tier JIT compiler: Turbofan and Turboshaft.
Maglev and Turbofan
As mentioned, V8 has multi-tier JIt compiler. Maglev is a mid-tier JIT compiler. Turbofan and Turboshaft produce highly optimized code but takes longer to compile.
| Compiler | Compile Speed | Optimization Level | Structure |
|---|---|---|---|
| Maglev | Fast | Lower optimization | Simple |
| Turbofan | Slower | Higher optimization | Complex |
V8’s tiering manager decides which compiler to use for given function by its decision logic.
Turbolev
The name comes from maglev + turboshaft. As you might guess, it’s a project aimed at replacing the Turbofan compiler frontend, using Maglev’s IR as the new starting point.
The previous top-tier JIT compiler used Turbofan as its frontend and Turboshaft as its backend. Turbofan employed a Sea of Nodes for optimization, rather than the more conventional CFG (Control Flow Graph)-based approach. While theoretically powerful, but it had some practical drawbacks in complexity and maintainability.
To address these issues, the idea is build the Turboshaft backend graph from the mid-tier compiler, Maglev.
For more read about backgrounds and beginning of this project: Land ahoy: leaving the Sea of Nodes · V8 by Darius :).
How I join this project?
For a few years, I contributed JS feature surface layer area of the V8 project. However, I realized that memory managements and actual JIT compiler were still ‘black box’ to me. As opportunities to implement new ECMAScript features became harder to find as an external contributor. So I decided to expand my contribution area to look inside the black box and expand my opportunities.
I remembered that Darius had reviewed the JIT part of my Float16Array CLs. And he recently published the article on v8.dev about turbolev. I sent him an email to see if I can help something.
Hi Darius,
I’ve noticed that it’s getting a bit tough to find contribution opportunities related to ECMAScript features as an external contributor. So I was wondering—are there any areas in the compiler side (like Turboshaft or Maglev), or GC/memory stuff, where I could possibly help out?
I’d love to learn more and hopefully get involved in a broader range of work in V8.
–
Regards,
Seokho
He generously suggests the turbolev project! (With so so detailed explanation :))
Following his guidance, I decided to join the project. Firstly, I’d like to find out easiest one.
The first target was Math.atan2. It seemed like a good candidate because there was an existing code path for Math.pow that handled similar IEEE754 binary operation.
And I created a draft CL and emailed some questions about it to Darius, Marja, Victor, and Leszek. They kindly explained it to me and helped me to run pinpoint the performance measurement tool for Googler.
Contributions
Starting from optimizing Math.atan2, I contributed about 4 CLs.

I optimized:
Math.atan2Math.sqrtArray.prototype.at
… and some refactors.
I’ll introduce one of them:
Implement Math.sqrt turbolev - Support Math.sqrt function to mid and top tier compiler in V8.
There are 61% of performance enhanced.
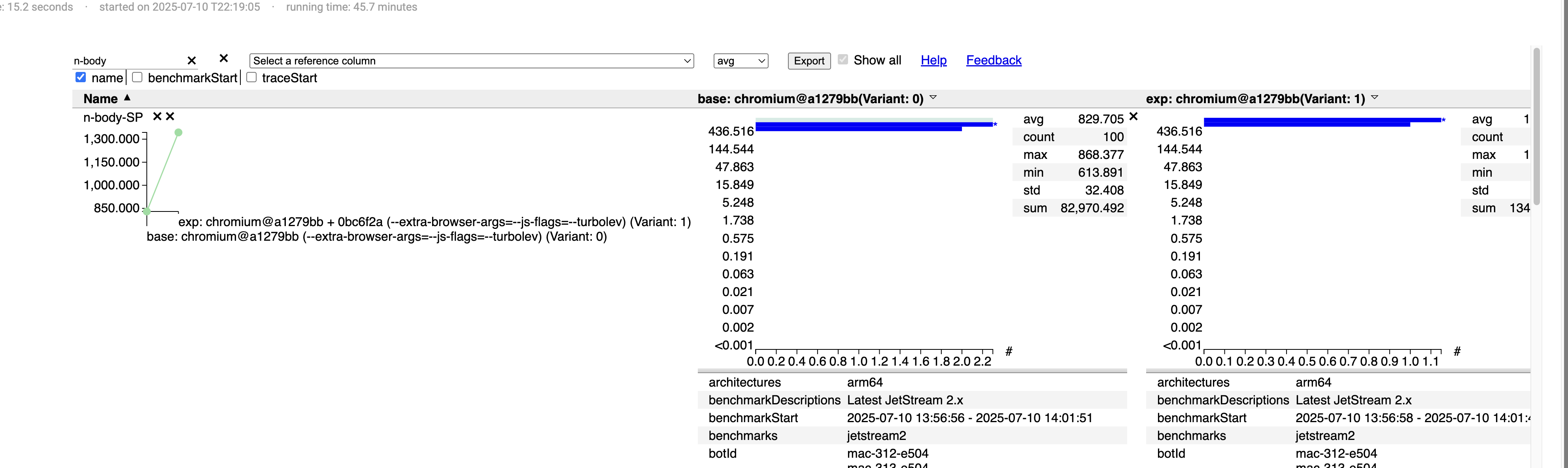
In the code review, Victor said it was amazing!

Let’s explain how do I optimize this:
I added a maglev IR node.
class Float64Sqrt : public FixedInputValueNodeT<1, Float64Sqrt> {
using Base = FixedInputValueNodeT<1, Float64Sqrt>;
public:
explicit Float64Sqrt(uint64_t bitfield) : Base(bitfield) {}
static constexpr OpProperties kProperties = OpProperties::HoleyFloat64();
static constexpr
typename Base::InputTypes kInputTypes{ValueRepresentation::kHoleyFloat64};
Input& input() { return Node::input(0); }
void SetValueLocationConstraints();
void GenerateCode(MaglevAssembler*, const ProcessingState&);
void PrintParams(std::ostream&) const;
};
And registered MathSqrt in maglev graph builder maglev-graph-builder.h
...
V(MathRound) \
V(MathSqrt) \
V(MathClz32) \
V(SetPrototypeHas) \
...
That macro creates reducer function declaration . So C++ compiler told me to create a implementation.
MaybeReduceResult MaglevGraphBuilder::TryReduceMathSqrt(
compiler::JSFunctionRef target, CallArguments& args) {
if (args.count() < 1) {
return GetRootConstant(RootIndex::kNanValue);
}
if (!CanSpeculateCall()) {
ValueRepresentation rep = args[0]->properties().value_representation();
if (rep == ValueRepresentation::kTagged) return {};
}
ValueNode* value =
GetFloat64ForToNumber(args[0], NodeType::kNumber,
TaggedToFloat64ConversionType::kNumberOrUndefined);
return AddNewNode<Float64Sqrt>({value});
}
This reducer attempts to simplify or convert a high-level operation (like a JS call to Math.sqrt) into a more optimized, lower-level IR node (Float64Sqrt). Which will be used in “turbolev” for top tier JIt and “maglev” for mid-tier JIT.
For Mid-Tier Maglev - arm64 arch:
void Float64Sqrt::SetValueLocationConstraints() {
UseRegister(input());
DefineSameAsFirst(this);
}
void Float64Sqrt::GenerateCode(MaglevAssembler* masm,
const ProcessingState& state) {
DoubleRegister value = ToDoubleRegister(input());
DoubleRegister result_register = ToDoubleRegister(result());
__ fsqrt(result_register, value);
}
Now, when it JIT compiles this code, the Float64Sqrt node will generate machine instruction fsqrt for arm64 arch. Similarly, for x64, it will generate sqrtsd SSE instruction.
For Top-Tier turbolev compilation:
The Float64Sqrt node consumed by turbolev-graph-builder.
maglev::ProcessResult Process(maglev::Float64Sqrt* node,
const maglev::ProcessingState& state) {
SetMap(node, __ Float64Sqrt(Map(node->input())));
return maglev::ProcessResult::kContinue;
}
This creates Float64Sqrt Turboshaft Graph Node, using the coresponding node from the Maglev as input. From here, Turboshaft’s powerful CFG-based backend can perform further optimizations like Loop Unrolling, Store Elimination, and advanced Register Allocation.
So, When Math.sqrt becomes hot and stable, the tiering manager can trigger a Turbolev compilation. (While this will likely generate the same machine instruction, the key benefit is that Turboshaft can now apply its powerful optimizations to all the surrounding code.)
Concluding
Through this work, I’ve gained much more familiarity with the Maglev and Turbolev areas of V8. There are still many unimplemented functions and opportunities to help - There are many yet unimplemented functions. I’ll continue contributing to get more comfortable here, and the, expand other areas like WASM or memory or something else!
Thanks Darius, Marja, Victor, Leszek to gives great guide and code review :).