Introduction
In this post, I share the story of implementing Float16Array as an external contributor to V8, focusing on the final JIT optimizations in TurboFan and Turboshaft. Over several months, I engaged in weekly syncs with Google engineer Shu-Yu Guo and navigated platform-specific challenges to achieve significant performance improvements.
Float16Array
Float16Array is a TypedArray like Float32Array or Uint32Array. It works with 16bit floating point numbers (float16, half precision). It provides a more memory-efficient way to handle floating-point data compared to Float32Array and Float64Array, while still maintaining reasonable precision for certain use cases.
The Float16Array can be used to optimize performance and memory usage in web and JavaScript based applications, particularly in fields that require fast numerical computations such as WebGPU, WebGL based applications.
What is V8 and TUrBoFan ?
Before we begin, let me briefly introduce turbofan and turboshaft and V8 that I contribute.
What is V8?
V8 is a Javascript Engine to execute javascript code. (Simply) V8 has large-scale pipeline to execute and optimize javascript and WASM. It powers Chromium(which is foundation of Chrome, Edge, Whale, …etc.), Node.js, Deno.
V8 (JavaScript engine) - Wikipedia
What is the TurboFan?
As you know, JS is executed on the interpreter. But it normally slower than native language(C, C++).
Turbofan is a optimizer to catch up that performance gap.
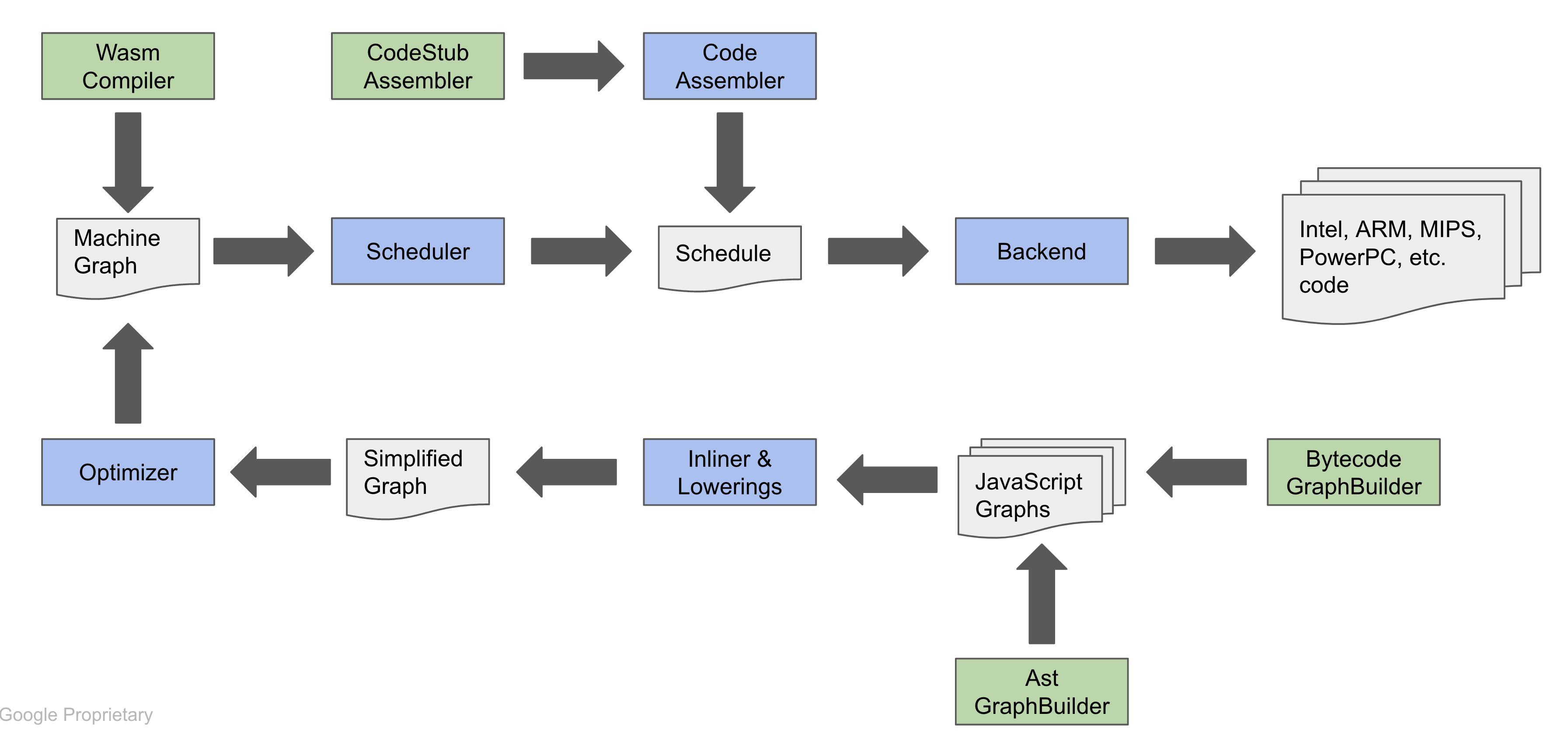
In this post, I won’t put the all details. Maybe, I’ll post later when I can.
Above picture, there are input called ByteCodeGraph that is a graph represents V8 Javascript Bytecode. And output results is a machine specific code. When some functions or operations get hot(Executed frequently), It will execute the pipeline and do optimize. And run as machine code.
Simply, The turbo engine for V8 to make faster. By JIT.
Turboshaft is another a control-flow graph intermediate representation (CFG-IR), between turbofan and machine executable. Final result of Turboshaft will be executable machine code.
What is the JIT?
JIT, or Just-In-Time, is a technology used in computing to optimize performance. It compiles code just before it is executed, rather than ahead of time. This approach allows programs to run faster by optimizing code for the specific environment it’s running on.
Just-in-time compilation - Wikipedia
Histories
From Beginning
I’m an open source contributor working as a hobby.
I implemented Float16Array, Math.f16round and related DataViews defined in the spec in Mar 2024 (further information: blog post)
The code review process began in Dec 2023. There are 70 patchsets and 80+ file changes made. Before code review, the implementation stage took almost 3Q and 4Q 2023 of my free time to achieve it. IT WAS A MASSIVE.
The reviewers and I agreed that we could separate the implementation of feature and turbofan JIT support due to the changes are already LARGE. As a result, I added always deoptimization code in here. This code thankfully improved by Darius.
At the end of Mar 2024, I thought Float16Array was ready to ship. I sent an email to Shu asking about “are we ready for the Intent to Ship process?”.
The response was that we need to address the deoptimization code that I described above. At least we should call our built-in implementation of the software emulation via in fp16.h. My understanding was to call the runtime function to call our builtin operation after the turbofan pipeline.
Now I can tell what that mean. But at the moment, I needed to figure out what and how turbofan work. I started learning and reading, writing turbofan code at most of my free time (especially Sunday). I implemented some pipeline steps to call ‘convert float16 value’ builtin operation.
And….. Unfortunately, In 2Q 3Q, I have to change my priorities for my spare time prepare for an exam.
The time flew by so fast; I just realized I’m already in Q4. Sometimes I got an mail or working related in Float16Array. That was a bit scary with worried about slowness and lose the opportunity. I mean, at that time.
Beginning of 4Q, I got an email from Shu: Now Float16Array is ready for development and float16 <> float64 conversion for x64 and ARM is in progress by Ilya.
I changed a plan from ‘just calling builtin operation’:
- Wait until the machine-support conversions are ready.
- Review the conversion codes, to determine the scope.
- Remove the “always unoptimize” code in the js-native-context-specialization
- Add turbofan nodes through the turbofan pipelines per each step to support Float16Array.
- Connect the pipeline or node implemented by Ilya (I may need to investigate which step is the best fit).
- Add a fallback for unsupported float16 machines (I imagined that it can possible to call runtime operation that using uint16 as we previously implemented)
And time has passed to Nov. Until that time I read codes and try to implement above plan when I was available. Some day of Nov, I noticed that some changes at the upstream are partly conflicted with my experimental Float16Array code. I realized that something I mentioned above the about worrying about can be happen like conflict. And I thought that possibly make duplicate work. I was a bit confused about how to handle this. I felt like lost my way.
So I decided that I need to share more frequently about the implementation status and the progress, and where I have blocked. In the mid-Nov. I sent an email to share about the status of my implementation and to ask for a weekly sync expecting some mentoring or managing:
Hi syg,
And I think the turbofan and turboshaft code is much more complex than I thought… Is there any mentoring system or programme for this?
I may need to tighten the feedback loop for myself to release in this year. If you don’t mind, can I send some kind of weekly or some periodic update email that might include what I’m considering or what I’m stuck on?
Regard Seokho
When I sent the above email, I had some small fears about exposing my lack of code understanding or ability. And also of wasting his time and losing the contribution opportunity.
Thankfully, he said yes. I was very happy.
Progression:
So finally, I started weekly sync.
First week - Sync the Context
In the first week, I spent time preparing to provide histories and context above. I opened temporary WIP CL to provide context. The contents of the email filled up with the above stories haha. And I hit a submit button, hoping to find the way.
Following is part of the email content:
B. The plan:
Sooo, It seems machine support is now possible thanks to Ilya’s changes. I noticed the following in the Turboshaft graph builder:
UNARY_CASE(TruncateFloat64ToFloat16RawBits, TruncateFloat64ToFloat16RawBits).One remaining task appears to be removing the force-deoptimize code in
src/compiler/js-native-context-specialization.ccand adding aUNARY_CASEforChangeFloat16ToFloat64.Additionally, should we consider retaining software calculations for cases where machines do not support FP16 operations? If so, where would be the best place to handle this in Turbofan?
So… the question is whether my assumption about the remaining task is correct.
C. Next action plan:
I feel a bit uncertain about the next steps, so I’m looking forward to syncing wit Shu about B. The Plan part.
And Shu suggest detailed plan. Thank you very much :)
The plan overview:
- Write a microbenchmark
- Remove deopts for float64->float16 (i.e. writing into Float16Array)
- If simpler, introduce a new truncation operator
- Lower that new operator to TruncateFloat64ToFloat16RawBits operator where supported (i.e. get the non-software emulation path working)
- Lower that new operator to a C call to do the truncation where the operator is unsupported (i.e. get the software emulation path working)
- Repeat for float16->float64 (i.e. reading out of Float16Array) working.
- Verify that microbenchmarks have improved.
Second Week - Execute what we synced
In the second week, I abandoned the wip CL for sync. And write down a microbenchmark code:
const ITERATION = 100000000
const array = new Float16Array(10000)
function store(i) {
array[i % 10000] = 1.1 + 0.01 * (i % 10)
}
function load(i) {
return array[i % 10000]
}
for(let i = 0; i< ITERATION; i+=1) { // heater
store(i)
}
let sum = 0;
for(let i = 0; i< ITERATION; i+=1) { // heater
load(i)
}
console.log("N = ", ITERATION)
console.time('store');
for(let i = 0; i< ITERATION; i+=1) {
store(i)
}
console.timeEnd('store');
console.time('load');
sum = 0;
for(let i = 0; i< ITERATION; i+=1) {
sum+= load(i)
}
console.timeEnd('load');
console.log("SUM = ", sum)
console.log("BYTE LENGTH: " ,array.BYTES_PER_ELEMENT)
Execution time (Note that the result is based on always deoptimization):
N = 100000000
console.timeEnd: store, 2242.493000
console.timeEnd: load, 1853.342000
This week, I focused on the ‘store’ path of the source code and graph building to process float16 conversion. While implementing some turbofan nodes, I saw the results on turbolizer and spent time to debug the representation change phase.
However, I didnt think this graph build/modification is correct. (Because I put some code that does not seem to be fit)
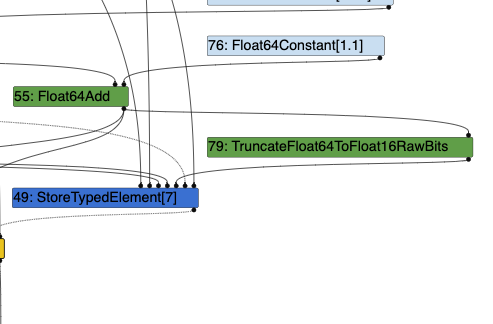
So I send sync email to explain above contain following:
…
I found a code chunk of calling external reference functions but I need to figure out how to connect with our TruncateFloat64ToFloat16RawBits.
PLAN: 5.1: Investigate where I should call / process platform specific code to process TruncateFloat64ToFloat16RawBits node from your suggestion ‘machine_lowering’ code. (Maybe if there are some existing codes there will be great)
5.2: Write the code to call the software/hardware support code.
5.3: Find out how to separate Float32 in representation-change steps.
Third Week - Software Emulation Work!
The third time sync was Dec 1 2024. It was a Sunday and very first snow day in South Korea. (I found from the email that I shared about this to Shu!)
I removed kJSFloat16TruncateWithBitcast codes which I assumed that was not necessary and it caused ambiguous duplicated name via some macro generated. And finally wrote the lowering reducer to call external reference function call.
Unfortunately, I faced an issue with illegal hardware instruction.
devsdk@Dave ~/workspace/chromium/v8/v8 % ./out/arm64.debug/d8 --js-float16array ~/workspace/chromium/playground/float16array_float16.js
zsh: illegal hardware instruction ./out/arm64.debug/d8 --js-float16array
I thought this was happened by some kind of issue with the M1 arm64. (Later it turns out to be caused by an infinity recursive call).
With an external reference call (Simply means just call C function), It seems to be over 200% faster, even though these are not hardware operations.
devsdk@Dave ~/workspace/chromium/v8/v8 % ./out/x64.release/d8 --js-float16array ~/workspace/chromium/playground/float16array_float16.js
N = 100000000
console.timeEnd: store, 770.435000
SUM = 0
BYTE LENGTH: 2
and share the plan of the next week; it contains:
- Enhance graph building
- implement the loading code path
- Investigates some issue..
Forth Week - Weird week
Forth week. It was tough week. Because the president of South Korea declared a material law last Wednesday and the National Assembly stopped it
And Shu also said “I saw that on the news! It sounds like a turbulent time; this CL should be the least of your worries” in email. 🤣
Personally I don’t have enough time in this week. So my works were a bit small.
I implemented software emulation load code path and implement DoNumberToFloat16RawBits.
The plan of next week was:
- Run the microbenchmark
- Investigate whether kJSFloat16TruncateWithBitcast is really not needed which I removed in last week.
- implement machine-support code for “load”.
Fifth Week - Hardware instruction works but another issue come
The fifth sync was also very short. Because I have a trip plan to Japan. Until my trip, I implement the hardware support path and also figure out why ‘illigal instruction issue’
Email content:
Hi syg
I’m going on an away trip this weekend, so I’m trying to sync now.
And with hardware support (only for store yet):
devsdk@Dave ~/workspace/chromium/v8/v8 % ./out/arm64.release/d8 –js-float16array ~/workspace/chromium/playground/float16array_float16.js
N = 100000000
console.timeEnd: store, 133.083000
(It super fast)
I kept kJSFloat16TruncateWithBitcast to use instruction selection to fix illigal instruction issue that we mentioned in previous email on arm64. It was caused by by infinite call loop TrucateFloat64ToFloat16RawBits -> ReduceXXX -> TrucateFloat64…
The arm64 native support that kept kJSFloat16TruncateWithBitcast through ReduceIfReachableChange makes the x64 software path that implemented our reducers is broken. I’ll have a look at it after my trip.
And some conversation with the trip. (I took this picture!)

Finally I implemented load path.
After that, I tried to run all checks (CI testing).
And.. finally! With some code clean up, the CL has been ready for review.
The final benchmark!
Without any optimization (original)
N = 100000000
console.timeEnd: store, 2242.493000
console.timeEnd: load, 1853.342000
Software calculation (calling the fp16.h):
N = 100000000
console.timeEnd: store, 379.250000
console.timeEnd: load, 606.833000
arm64 hardware operation:
N = 100000000
console.timeEnd: store, 128.042000
console.timeEnd: load, 603.542000
It optimize over 500% for store, and 300% for load!
Sixth Week - THE REVIEW PHASE
Now…. review phase!
Some codes are changed:
I created float16-lowering-reducer.h which is defined as a pipeline phase in turboshaft to create machine code by hardware support. (It has been deleted by further work though!) And I changed the target that external reference function for changing float64 to float16. Finally, I added various edge cases in testcode defined in tc39/test262:
const edgeCases = [
// an integer which rounds down under ties-to-even when cast to float16
{ input: 2049, expected: 2048 },
// an integer which rounds up under ties-to-even when cast to float16
{ input: 2051, expected: 2052 },
// smallest normal float16
{ input: 0.00006103515625, expected: 0.00006103515625 },
// largest subnormal float16
{ input: 0.00006097555160522461, expected: 0.00006097555160522461 },
// smallest float16
{ input: 5.960464477539063e-8, expected: 5.960464477539063e-8 },
// largest double which rounds to 0 when cast to float16
{ input: 2.9802322387695312e-8, expected: 0 },
// smallest double which does not round to 0 when cast to float16
{ input: 2.980232238769532e-8, expected: 5.960464477539063e-8 },
// a double which rounds up to a subnormal under ties-to-even when cast to float16
{ input: 8.940696716308594e-8, expected: 1.1920928955078125e-7 },
// a double which rounds down to a subnormal under ties-to-even when cast to float16
{ input: 1.4901161193847656e-7, expected: 1.1920928955078125e-7 },
// the next double above the one on the previous line one
{ input: 1.490116119384766e-7, expected: 1.7881393432617188e-7 },
// max finite float16
{ input: 65504, expected: 65504 },
// largest double which does not round to infinity when cast to float16
{ input: 65519.99999999999, expected: 65504 },
// lowest negative double which does not round to infinity when cast to float16
{ input: -65519.99999999999, expected: -65504 },
// smallest double which rounds to a non-subnormal when cast to float16
{ input: 0.000061005353927612305, expected: 0.00006103515625 },
// largest double which rounds to a subnormal when cast to float16
{ input: 0.0000610053539276123, expected: 0.00006097555160522461 },
{ input: NaN, expected: NaN },
{ input: Infinity, expected: Infinity },
{ input: -Infinity, expected: -Infinity },
// smallest double which rounds to infinity when cast to float16
{ input: 65520, expected: Infinity },
{ input: -65520, expected: - Infinity },
];
Merged!
Finally the CL is merged on Jan 27. It was almost half of a year. Now I finally got a little bit familiar with the turbofan/turboshaft pipelines!
I was expecting this to be done by the end of 2024. But now at the end of Jan.
Starting from the frontend of JS API to the JIT machine code generator backend. It was a bit long .
CL: chromium-review.googlesource.com/c/v8/v8/+/6043415
And between the merge and preparing the ship, I’ve been travelling around the States for traveling. I met Shu! And also this CL was has been merged when I stayed in San Jose, CA, USA.
 We talked about careers and contributions to V8 stuffs!
We talked about careers and contributions to V8 stuffs!
Probably, It’s better chance to the another post of the blog! I’ll write later about my traveling.
Anyway, now we have few steps left to ship this feature.
Prepare to ship
We need to +3 LGTMs to ship feature as public on blink-dev google group. It will be reviewed by Intended to Ship (AKA I2S).
Finally, Feb 14 2025, It has been approved on my intent to ship!
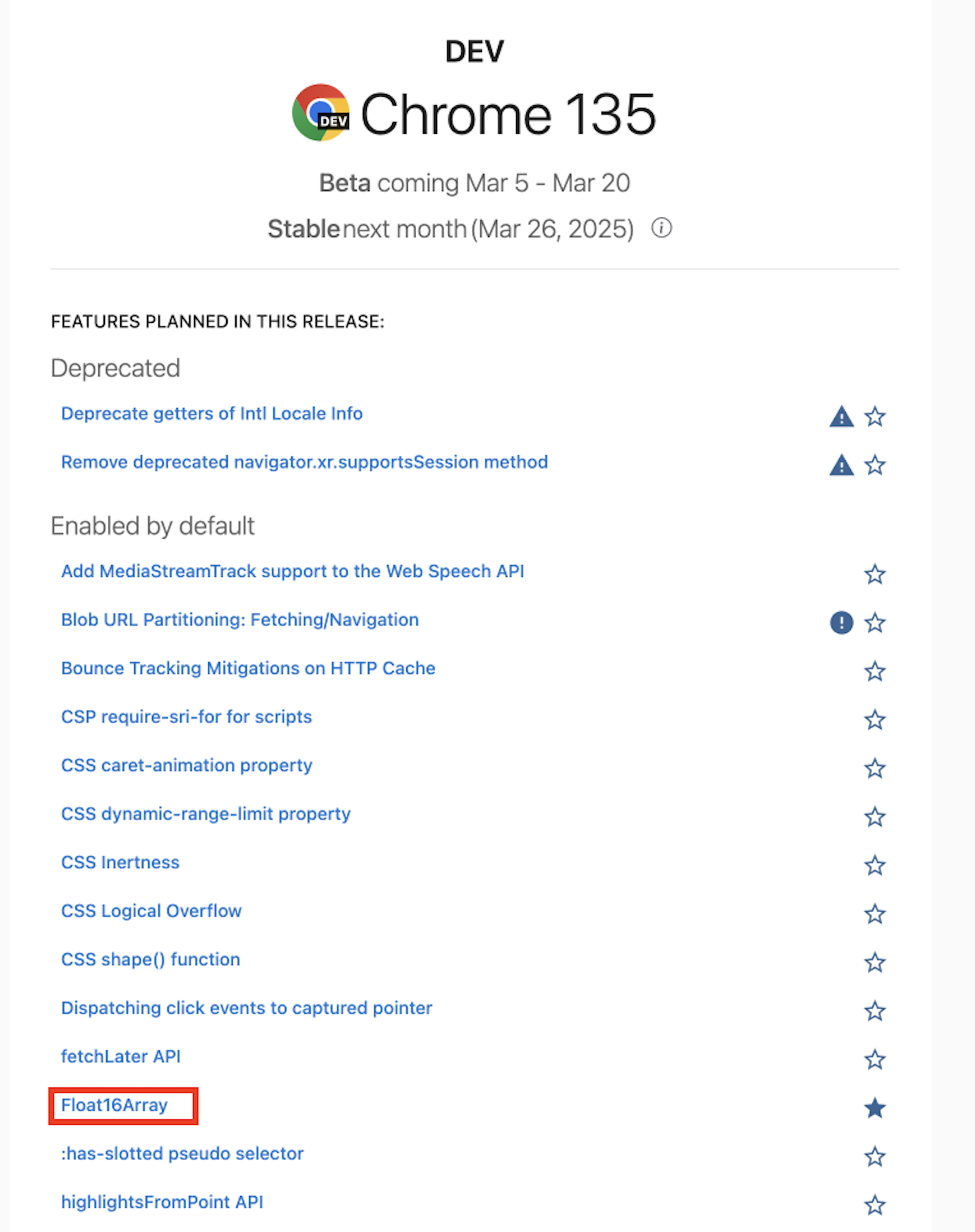
And… Ship!
Shu fixed some of the bugs found detected by the fuzzers on the blink side. After a week of waiting to check the problems detected by some automation, I finally flipped the feature flag to enabled by default! Another feature I was involved with has been released to the world.
You can use the new Float16Array in Chrome M135 (released mid March 2025)!
Feature Entry: https://chromestatus.com/feature/5164400693215232