Introduction
이 글에서는 V8의 외부 컨트리뷰터로서 Float16Array를 구현한 이야기를 공유하면서 TurboFan과 Turboshaft의 최종 JIT 최적화에 초점을 맞춥니다. 몇 달에 걸쳐 저는 Google 엔지니어 Shu-Yu Guo와 매주 동기화를 진행하며 플랫폼별 과제를 해결하여 상당한 성능 향상을 달성했습니다.
Float16Array
Float16Array는 Uint32Array 혹은 Float32Array와 같은 타입 배열입니다. 16비트 부동 소수점 숫자(float16, 반정밀도)로 작동합니다. 특정 사용 사례에 적합한 정밀도를 유지하면서 Float32Array 및 Float64Array에 비해 부동 소수점 데이터를 처리하는 메모리 효율적인 방법을 제공합니다.
Float16Array는 웹 및 JavaScript 기반 애플리케이션에서 성능과 메모리 사용량을 최적화하는 데 사용할 수 있으며, 특히 WebGPU, WebGL 기반 애플리케이션과 같이 빠른 숫자 연산이 필요한 분야에서 유용하게 사용할 수 있습니다.
What is V8 and TUrBoFan ?
본격적으로 시작하기 전에 Turbofan, Turboshaft, 그리고 제가 기여하는 V8에 대해 간략히 소개하겠습니다.
What is V8?
V8은 JavaScript 코드를 실행하기 위한 자바스크립트 엔진입니다. V8에는 자바스크립트와 WASM을 실행하고 최적화하기 위한 대규모 파이프라인이 있으며, Chromium(Chrome, Edge, Whale 등의 기반), Node.js, Deno 등을 구성합니다.
V8 (JavaScript engine) - Wikipedia
What is the TurboFan?
아시다시피 JS는 인터프리터 위에서 실행되지만, 일반적으로 네이티브 언어(C, C++ 등)보다 느립니다.
Turbofan은 이러한 성능 격차를 좁히기 위한 최적화 도구입니다.
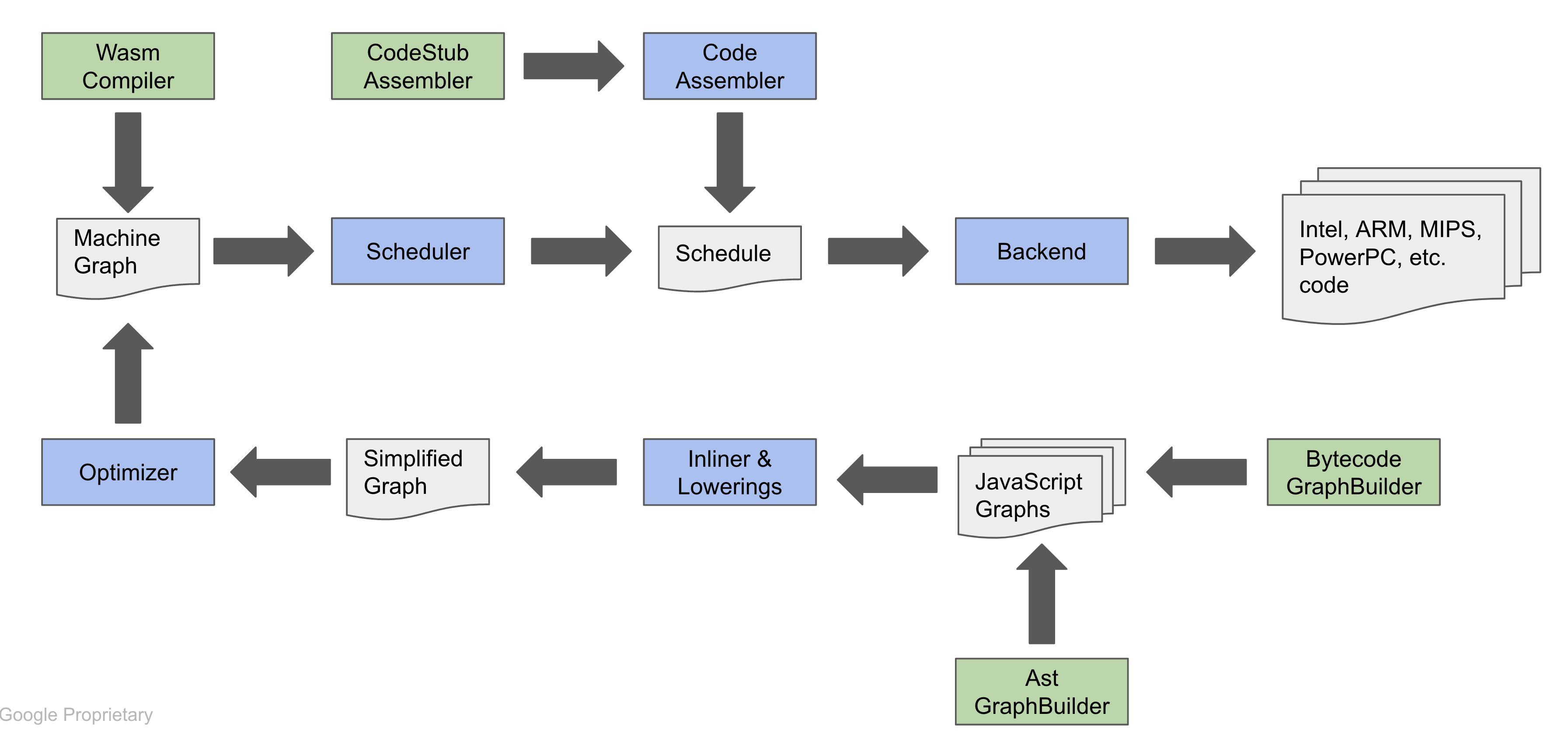
이 포스트에서는 모든 세부사항을 다루지 않을 겁니다. 기회가 된다면 따로 글을 작성하겠습니다. 위 그림을 보면, 입력으로 ByteCodeGraph(V8 자바스크립트 바이트코드에서 빌드된 그래프)가 있고, 출력은 타깃 머신별 코드를 생성해냅니다. 함수나 연산이 충분히 자주 호출되어 뜨거운 상태(자주 호출되는 상태)가 되면 파이프라인이 실행되어 최적화가 이뤄지고, 결국 머신 코드로 동작하게 됩니다.
Turboshaft 는 또 다른 제어 흐름 그래프 중간 표현(CFG-IR)으로, Turbofan과 머신 실행 코드 사이에 위치합니다. Turboshaft의 최종 결과는 실행 가능한 머신 코드가 됩니다.
JIT란?
JIT(Just-In-Time)는 컴퓨팅에서 성능을 최적화하기 위해 사용되는 기술로, 실행하기 전이 아닌, 실행 시점 직전에 코드를 컴파일합니다. 이~ 방식은 실행되는 환경에 맞춰 코드를 최적화할 수 있으므로, 프로그램이 더 빠르게 동작하도록 돕습니다.
Just-in-time compilation - Wikipedia
Histories
From Beginning
저는 여가시간에 취미로 기여하는 개인 기여자 입니다.
2024년 3월 스팩에 정의된 Float16Array, Math.f16round, 그리고 관련 DataView를 구현 했습니다.
코드 리뷰는 2023년 12월에 시작되었습니다. 70개의 패치셋과 80개 이상의 파일이 변경되고, 코드 리뷰 전 구현 단계에서 2023년 3~4분기의 개인 시간이 많이 투입될 정도로 거대한 프로젝트였습니다.(관련 포스트)
리뷰어들과 저는 변경이 너무 방대하니, 기능 구현과 Turbofan JIT 지원 부분을 분리하기로 합의했습니다. 결국 여기에서 항상 deoptimization하도록 하는 코드를 추가했는데, 이 코드는 이후 Darius에 의해 개선되었습니다.
2024년 3월 말, 저는 Float16Array가 릴리즈 준비가 되었다고 판단했고, Shu에게 “Intent to Ship 프로세스를 진행할 준비가 되었느냐”는 메일을 보냈습니다.
그에 대한 답변은, 제가 위에서 언급한 Deoptimization 코드를 해결해야 한다는 것이었습니다. 적어도 fp16.h 안에 있는 소프트웨어 에뮬레이션 함수를 호출해야 한다고 했습니다. 즉, Turbofan 파이프라인 이후에 런타임 함수를 호출하는 형태가 필요했습니다.
지금은 그 말이 어떤 의미인지 알지만, 당시에는 “Turbofan이 뭔지, 어떻게 동작하는지”를 알아내야 하는 상황이었습니다. 그래서 일요일 대부분의 시간을 투자해가며 Turbofan 코드를 읽고 작성하기 시작했고, ‘float16 값을 변환’하는 빌트인 함수를 호출하는 파이프라인 단계를 구현했습니다.
그러나… 2분기, 3분기에 개인 사정(시험 준비)으로 우선순위를 바꿔야 했습니다.
시간은 정말 빠르게 지나가 4분기가 되었습니다. 종종 Float16Array 관련 메일이나 작업이 오긴 했지만, 더딘 진행과 기회를 놓칠 수 있다는 불안감이 있었습니다.
4분기 초, Shu로부터 메일이 왔습니다. Float16Array는 이제 개발이 가능하고, x64와 ARM에서 float16 <-> float64 변환 작업을 Ilya가 진행 중이라는 내용이었습니다.
그래서 “내장 함수를 호출하자”라는 저의 기존 계획을 바꿔 다음과 같은 새로운 계획을 세웠습니다:
- 머신에서 float16 변환을 지원하는 패치가 준비될 때까지 대기
- 변환 코드를 검토해 범위를 파악
- js-native-context-specialization의 “Always Unoptimize” 코드를 제거
- 각 단계마다 Turbofan 노드를 연결해 Float16Array를 지원
- Ilya가 구현한 노드나 파이프라인과 연결 (어느 단계가 최적인지 조사 필요)
- float16을 지원하지 않는 머신을 위한 Fallback으로 (uint16을 사용하는) 런타임 함수를 호출하는 방안도 고려
시간은 흘러 11월이 되었고, 코드를 읽고 시간이 있을 때 위의 계획을 구현하려고 노력했습니다. 11월의 어느 날, 업스트림의 일부 변경 사항이 실험용 Float16Array 코드와 부분적으로 충돌하는 것을 발견했습니다. 위에서 언급한 것 처럼 충돌이 일어날 수 있다는 우려가 현실이 된 것 입니다. 그리고 이것이 중복 작업을 만들 수 있다고 생각했습니다. 어떻게 해야할 지 혼란스러웠고, 길을 잃은 것 같았습니다.
그래서, 구현 상태나 진행 상황, 그리고 막힌 부분을 더 자주 공유해야겠다고 결심했습니다. 11월 중순, 작은 멘토링이나 매니징 도움을 기대하며 “주간 싱크”를 요청하는 메일을 보냈습니다:
Hi syg,
And I think the turbofan and turboshaft code is much more complex than I thought… Is there any mentoring system or programme for this?
I may need to tighten the feedback loop for myself to release in this year. If you don’t mind, can I send some kind of weekly or some periodic update email that might include what I’m considering or what I’m stuck on?
Regard
Seokho
Hi syg,
Turbofan, Turboshaft 코드가 생각보다 훨씬 복잡한 것 같아요… 이에 대한 멘토링 시스템이나 프로그램이 있나요?
올해 안에 배포하려면 피드백 루프를 더 강화해야 할 것 같습니다. 괜찮다면 매주 또는 주기적으로 제가 고려하고 있는 사항이나 막혀 있는 사항을 포함한 업데이트 이메일을 보내도 될까요?Regard
Seokho
이 메일을 보낼 때, 제 코드 이해 부족이나 역량을 드러내고 시간을 뺏는 게 아닐까 걱정도 됐고, 기회를 잃게 되지 않을까 두려움도 있었습니다.
정말 기쁘게도 다행히 그가 좋다고 답해줬습니다.
Progression:
이렇게 해서 주간 싱크를 본격적으로 시작하게 되었습니다.
First week - Sync the Context
첫 주에는, 위의 히스토리와 맥락을 정리해 Shu에게 보여주기 위한 준비를 했습니다. 그리고 임시 WIP CL을 열어 현재 진행 상황을 공유했습니다. 이메일 내용도 위와 같은 히스토리로 가득 습니다. 길을 찾기를 바라면서 메일을 보냈습니다.
이메일 내용 일부를 발췌하면 다음과 같습니다:
B. The plan:
Sooo, It seems machine support is now possible thanks to Ilya’s changes. I noticed the following in the Turboshaft graph builder:
UNARY_CASE(TruncateFloat64ToFloat16RawBits, TruncateFloat64ToFloat16RawBits).One remaining task appears to be removing the force-deoptimize code in
src/compiler/js-native-context-specialization.ccand adding aUNARY_CASEforChangeFloat16ToFloat64.Additionally, should we consider retaining software calculations for cases where machines do not support FP16 operations? If so, where would be the best place to handle this in Turbofan?
So… the question is whether my assumption about the remaining task is correct.
C. Next action plan:
당시 다음 단계에 무엇을 해야할지 불확실한 느낌이 들어 B. 계획 부분에 대해 동기화하기를 기대했습니다.
그리고 Shu는 정말 고맙게도 디테일한 계획을 제시해주었습니다. :)
계획 요약:
- 마이크로벤치마크 작성
- float64->float16 저장(즉 Float16Array에 쓰기) 시의 Deoptimization 제거
- 필요하다면, 새로운 ‘truncation operator’ 추가
- 해당 새 오퍼레이터를 TruncateFloat64ToFloat16RawBits 오퍼레이터로 낮춤(lower) (즉 소프트웨어 에뮬레이션이 아닌 경로를 동작시키기)
- 지원 안 되는 환경에선 C 함수를 호출하여 truncation 처리(소프트웨어 에뮬레이션 경로)
- float16->float64 (즉 Float16Array에서 값 읽기)도 같은 방식으로 반복
- 마이크로벤치마크 성능이 향상되었는지 확인
Second Week - Execute what we synced
둘째 주에는, 첫 주에 싱크 용으로 만들어뒀던 WIP CL을 버리고, 간단한 마이크로벤치마크 코드를 작성했습니다:
const ITERATION = 100000000
const array = new Float16Array(10000)
function store(i) {
array[i % 10000] = 1.1 + 0.01 * (i % 10)
}
function load(i) {
return array[i % 10000]
}
for(let i = 0; i< ITERATION; i+=1) { // heater
store(i)
}
let sum = 0;
for(let i = 0; i< ITERATION; i+=1) { // heater
load(i)
}
console.log("N = ", ITERATION)
console.time('store');
for(let i = 0; i< ITERATION; i+=1) {
store(i)
}
console.timeEnd('store');
console.time('load');
sum = 0;
for(let i = 0; i< ITERATION; i+=1) {
sum+= load(i)
}
console.timeEnd('load');
console.log("SUM = ", sum)
console.log("BYTE LENGTH: " ,array.BYTES_PER_ELEMENT)
(이 코드는 “항상 Deoptimization” 상태에서의 결과) 실행 시간:
N = 100000000
console.timeEnd: store, 2242.493000
console.timeEnd: load, 1853.342000
이번주에는 주로 소스 코드의 ‘store’ 경로를 확인하면서, float16 변환을 처리하기 위해 Turbofan 노드를 어떻게 생성할지를 살폈습니다. turbolizer 를 사용해 그래프도 확인하고, representation change phase를 디버깅했습니다.
하지만 제가 생성한 그래프 빌드/수정 방법이 맞는 건지 확신이 서지 않았습니다. (쓰지 말아야 할 코드를 억지로 넣은 느낌이었거든요)
위에서 말한 어색하다고 느낀 지점을 포함해 메일로 공유했습니다.
…
I found a code chunk of calling external reference functions but I need to figure out how to connect with our TruncateFloat64ToFloat16RawBits.
PLAN: 5.1: Investigate where I should call / process platform specific code to process TruncateFloat64ToFloat16RawBits node from your suggestion ‘machine_lowering’ code. (Maybe if there are some existing codes there will be great)
5.2: Write the code to call the software/hardware support code.
5.3: Find out how to separate Float32 in representation-change steps.
외부 참조 함수를 호출하는 코드 덩어리를 찾았지만 TruncateFloat64ToFloat16RawBits와 연결하는 방법을 알아내야 합니다.
PLAN: 5.1: 제안하신 ‘machine_lowering’ 코드에서 플랫폼별 코드를 어디에서 호출/처리하여 TruncateFloat64ToFloat16RawBits 노드를 처리해야 하는지 조사합니다. (기존 코드를 알 수 있다면 좋을 것 같습니다.)
5.2: 소프트웨어/하드웨어 지원 코드를 호출하는 코드를 작성합니다.
5.3: Float32를 representation-change 단계에서 분리하는 방법을 알아봅니다.
Third Week - Software Emulation Work!
세 번째 싱크는 2024년 12월 1일이었습니다. 마침 일요일이었고, 한국에서 첫눈이 내리던 날이었네요. (이걸 Shu에게 메일로 얘기했더라고요!)
모호한 이름 충돌도 일으키고 있는 불필요한 kJSFloat16TruncateWithBitcast관련 코드를 제거했습니다.
드디어 lower reducer에서 외부 레퍼런스 함수 호출 코드를 작성했습니다.
그런데 arm64에서 illegal hardware instruction 문제가 생겼습니다:
devsdk@Dave ~/workspace/chromium/v8/v8 % ./out/arm64.debug/d8 --js-float16array ~/workspace/chromium/playground/float16array_float16.js
zsh: illegal hardware instruction ./out/arm64.debug/d8 --js-float16array
M1 arm64와 관련된 무언가라고 생각했습니다. (나중에 보니 무한 재귀 호출 문제가 원인이었어요)
외부 레퍼런스 함수(즉, C 함수를 직접 호출)로만 구현했을 때 하드웨어 연산이 아님에도 불구하고, 이미 200% 이상 속도가 빨라졌습니다!
devsdk@Dave ~/workspace/chromium/v8/v8 % ./out/x64.release/d8 --js-float16array ~/workspace/chromium/playground/float16array_float16.js
N = 100000000
console.timeEnd: store, 770.435000
SUM = 0
BYTE LENGTH: 2
그리고, 다음 주 계획을 공유했죠:
- 그래프 빌딩 개선
- load 경로 구현
- 몇 가지 이슈 조사…
Forth Week - Weird week
네 번째 주. 약간 이상하고 힘든 한 주였습니다. 모두가 기억하듯 대통령이 지난 수요일에 계엄령을 선포했다가 국회에서 중지시켰거든요…
그리고 Shu도 이메일에서 “뉴스에서 봤어요! 격동의 시기인 것 같은데, 이번 CL은 걱정하지 않아도 될 것 같습니다”라고 답을 보냈습니다. 🤣
개인적으로도 이번 주에는 시간이 넉넉하지 않아 작업량이 적었습니다.
그래도 load 경로를 구현하고, DoNumberToFloat16RawBits라는 함수를 구현했습니다.
다음 주 계획:
- 마이크로벤치마크 실행
- 제가 제거했던 kJSFloat16TruncateWithBitcast가 정말 필요 없는지 확인
- “load”에 대한 머신 지원 코드 구현
Fifth Week - Hardware instruction works but another issue come
다섯 번째 싱크도 시간이 짧았습니다. 일본 여행 계획이 있었거든요. 여행 전까지, 하드웨어 지원 경로를 구현하고, 왜 ‘illegal instruction’ 이슈가 생겼는지 파악했습니다.
Email content:
Hi syg
I’m going on an away trip this weekend, so I’m trying to sync now.
And with hardware support (only for store yet):
devsdk@Dave ~/workspace/chromium/v8/v8 % ./out/arm64.release/d8 –js-float16array ~/workspace/chromium/playground/float16array_float16.js
N = 100000000
console.timeEnd: store, 133.083000
(It super fast)
I kept kJSFloat16TruncateWithBitcast to use instruction selection to fix illigal instruction issue that we mentioned in previous email on arm64.It was caused by by infinite call loop TrucateFloat64ToFloat16RawBits -> ReduceXXX -> TrucateFloat64…
The arm64 native support that kept kJSFloat16TruncateWithBitcast through ReduceIfReachableChange makes the x64 software path that implemented our reducers is broken. I’ll have a look at it after my trip.
안녕하세요. Syg!
이번 주말에 여행을 떠날 예정이라 지금 메일을 보냅니다.
그리고 하드웨어 지원(아직 스토어에만 해당)도 제공됩니다:
devsdk@Dave ~/workspace/chromium/v8/v8 % ./out/arm64.release/d8 –js-float16array ~/workspace/chromium/playground/float16array_float16.js
N = 100000000
console.timeEnd: store, 133.083000
(매우 빠릅니다)
이전 이메일에서 언급 한 illigal instruction 문제를 해결하기 위해 명령어 선택을 사용하기 위해 kJSFloat16TruncateWithBitcast를 유지했습니다.이 문제는 무한 호출 루프 TrucateFloat64ToFloat16RawBits -> ReduceXXX -> TrucateFloat64…로 인해 발생했습니다.
reduceIfReachableChange를 통해 kJSfloat16TruncateWithBitcast를 유지했던 arm64 네이티브 지원 덕분에 구현했던 Reducer의 x64 소프트웨어 경로가 깨졌습니다. 여행 후에 한번 살펴보겠습니다
그리고 일본 여행 관련 얘기도 좀 했어요. (이 사진을 찍었습니다!)

결국 software emulation load 경로도 구현했습니다.
이후, 전체 테스트를 돌려봤습니다.
그리고 마침내! 코드 정리를 조금 거친 뒤 리뷰를 받기 위한 CL을 준비했습니다.
최종 벤치마크 결과:
Without any optimization (original)
N = 100000000
console.timeEnd: store, 2242.493000
console.timeEnd: load, 1853.342000
Software calculation (calling the fp16.h):
N = 100000000
console.timeEnd: store, 379.250000
console.timeEnd: load, 606.833000
arm64 hardware operation:
N = 100000000
console.timeEnd: store, 128.042000
console.timeEnd: load, 603.542000
store의 경우 약 500% 이상, load는 약 300% 향상되었습니다!
Sixth Week - THE REVIEW PHASE
이제… 리뷰 단계입니다!
변경된 코드 중 핵심을 요약하면:
하드웨어 지원을 통해 머신 코드를 생성하기 위해 터보샤프트에서 파이프라인 단계로 정의된 float16-lowering-reducer.h를 만들었습니다. (추후 추가 작업으로 삭제되었습니다!) 그리고 float64를 float16으로 변경하기 위한 외부 참조 함수의 대상을 변경했습니다. 마지막으로 tc39/test262에 정의된 테스트코드에 다양한 edge case를 추가했습니다.
const edgeCases = [
// an integer which rounds down under ties-to-even when cast to float16
{ input: 2049, expected: 2048 },
// an integer which rounds up under ties-to-even when cast to float16
{ input: 2051, expected: 2052 },
// smallest normal float16
{ input: 0.00006103515625, expected: 0.00006103515625 },
// largest subnormal float16
{ input: 0.00006097555160522461, expected: 0.00006097555160522461 },
// smallest float16
{ input: 5.960464477539063e-8, expected: 5.960464477539063e-8 },
// largest double which rounds to 0 when cast to float16
{ input: 2.9802322387695312e-8, expected: 0 },
// smallest double which does not round to 0 when cast to float16
{ input: 2.980232238769532e-8, expected: 5.960464477539063e-8 },
// a double which rounds up to a subnormal under ties-to-even when cast to float16
{ input: 8.940696716308594e-8, expected: 1.1920928955078125e-7 },
// a double which rounds down to a subnormal under ties-to-even when cast to float16
{ input: 1.4901161193847656e-7, expected: 1.1920928955078125e-7 },
// the next double above the one on the previous line one
{ input: 1.490116119384766e-7, expected: 1.7881393432617188e-7 },
// max finite float16
{ input: 65504, expected: 65504 },
// largest double which does not round to infinity when cast to float16
{ input: 65519.99999999999, expected: 65504 },
// lowest negative double which does not round to infinity when cast to float16
{ input: -65519.99999999999, expected: -65504 },
// smallest double which rounds to a non-subnormal when cast to float16
{ input: 0.000061005353927612305, expected: 0.00006103515625 },
// largest double which rounds to a subnormal when cast to float16
{ input: 0.0000610053539276123, expected: 0.00006097555160522461 },
{ input: NaN, expected: NaN },
{ input: Infinity, expected: Infinity },
{ input: -Infinity, expected: -Infinity },
// smallest double which rounds to infinity when cast to float16
{ input: 65520, expected: Infinity },
{ input: -65520, expected: - Infinity },
];
Merged!
마침내 이 CL은 1월 27일에 머지되었습니다. 거의 반년 걸렸네요. 그래도 이제 Turbofan/Turboshaft 파이프라인에 꽤 익숙해졌습니다!
2024년 말쯤 끝나리라 예상했는데, 결국 1월 말이 되었습니다.
자바스크립트 API 프론트엔드에서부터 JIT 머신 코드 생성 백엔드까지, 정말 길고도 긴 여정이었습니다.
CL: chromium-review.googlesource.com/c/v8/v8/+/6043415
그리고 머지 후, 배포 준비를 하는 동안엔 미국 여행을 다녔습니다. Shu도 만났고요! 제가 미국 산호세에 체류 중일 때 이 CL이 머지되었어요.

V8 관련 기여, 그리고 제 커리어에 대한 이야기도 나눴습니다!
아마 이 내용은 따로 여행 관련 포스트로 따로 다룰 수도 있을 것 같네요.
어쨌든, 이제 이 기능을 릴리즈하기 위해 몇 가지 단계를 더 진행해야 합니다.
Prepare to ship
Blink-dev 구글 그룹에서 +3 LGTMs를 받아야 기능을 공개할 수 있습니다. (흔히 말하는 Intended to Ship, I2S)
드디어 2025년 2월 14일, +3LGTMs를 받았습니다!
And… Ship!
퍼저에서 발견된 버그를 일부 수정하고 쪽에 테스트 케이스를 추가했습니다. 일부 자동화에서 감지된 문제를 확인하기 위해 일주일을 기다렸습니다.
Shu가 Blink 쪽에서 퍼저가 감지하는 버그를 일부 수정했습니다. 일부 자동화에서 감지된 문제를 확인하기 위해 일주일을 기다린 끝에 마침내 기능 플래그를 기본으로 활성화하도록 전환했습니다! 제가 개발에 참여한 다른 기능이 세상에 공개되었습니다.
Chrome M135(2025년 3월 중순 출시)부터 새로운 Float16Array를 사용할 수 있습니다!
Feature Entry: https://chromestatus.com/feature/5164400693215232